MIP – Modules Innovants Pédagogiques / Explorations numériques des archives de l’INA
- Porteurs du projet: Antonin Segault, Marta Severo
- Projets pédagogiques
- 2018 - 2024
- Commanditaires: INAthèque et EUR ArTeC
- Contact: Antonin Segault
- Archives, Datasprint, Éditorialisation, Humanités numériques, Médias, Visualisation
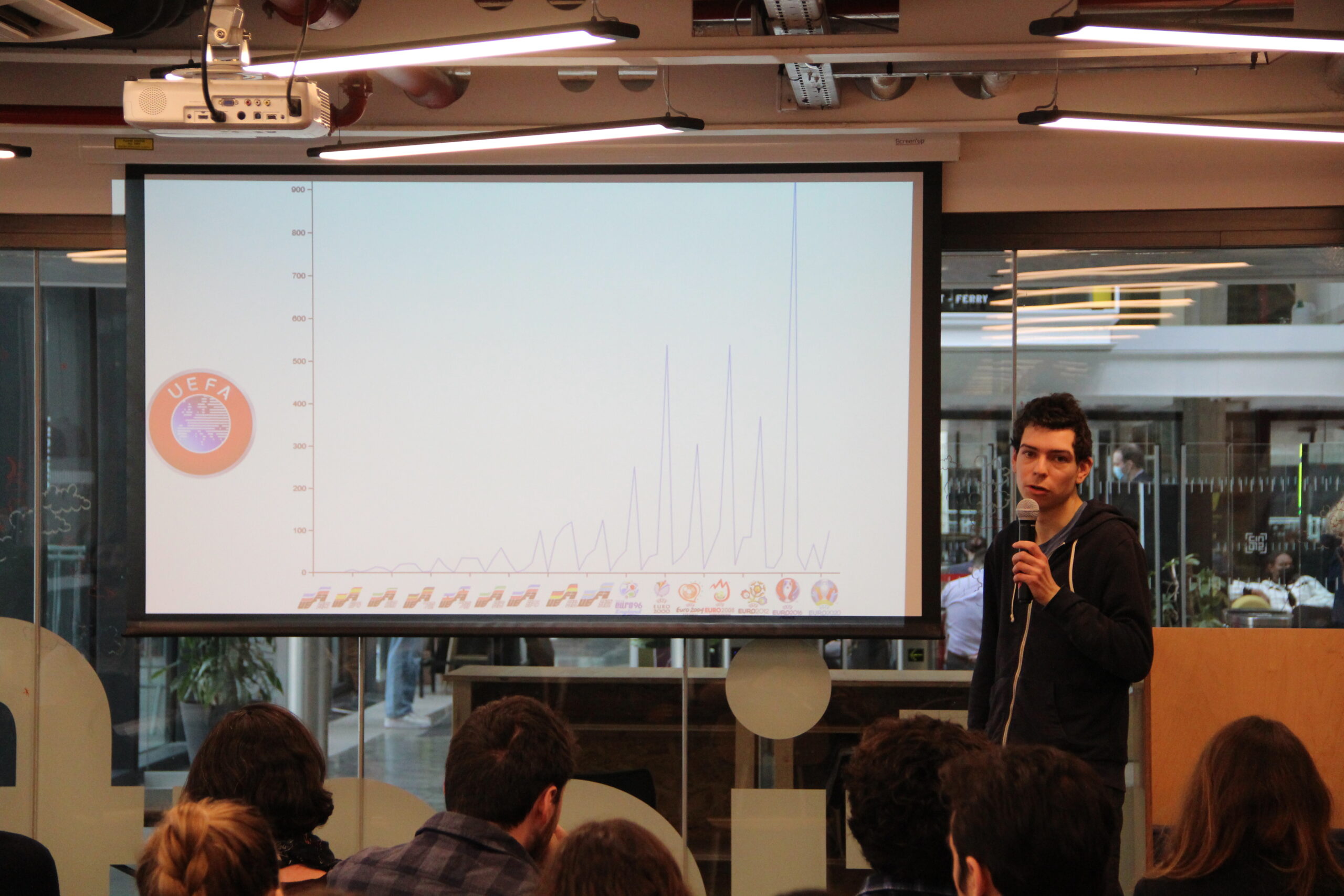
Le projet, mené en collaboration avec Marta Severo et Antonin Segault , professeure et maître de conférences à l’Université Paris Nanterre, porte à chaque édition sur un thème différent (« imaginaires du corps », Europe, Sport…). À partir de jeux de données, dont certains ont fait l’objet de traitement par les outils IA du service de la Recherche de l’INA (transcription, détections parole et visage hommes/femmes, reconnaissance de similarités …), les participants doivent produire des analyses qui renouvellent les pratiques d’exploitation scientifique des collections patrimoniales. Pendant 4 jours consécutifs, organisés en groupes et en format « Sprint », les participants ont alterné les séances de travail entre le Learning Lab de l’université de Nanterre et l‘INA thèque.
Concepts clés
Travail en groupe, données
Supports étudiés
Sélection de données dans les fonds de l’Inathèque (périmètre complet de la radio, de la télévision, et du Web, et ce, depuis l’origine de chacun des médias donc 22 millions d’heures de radio-TV, 60 millions de notices documentaires, 118 milliards d’URL Web archivées, presque 3 milliards de publications de comptes de réseaux sociaux)
Livrables
Exposés réalisés par des groupes d’étudiants à partir des jeux de données travaillés et de leur analyse
Méthodologie
Les étudiants, répartis en groupes, analysent des données sélectionnées dans les fonds de l’Inathèque et leur appliquent des traitements. Ils exploitent des outils de fouilles, des outils de visualisation qui permettent de donner à voir plus clairement des saillances, voire des manques dans ces jeux de données massives. Des ingénieurs chercheurs de l’INA appliquent également à certains de ces corpus et en amont de l’événement, des traitements de fouille, visualisation ou transcription qu’ils ont développés. Dans un temps réduit (une semaine), les groupes s’organisent pour faire « parler » e ces jeux de données à partir des traitements qu’ils ont appliqués pendant la durée du sprint. Ils produisent enfin des analyses et un rendu le dernier jour du sprint.
Résultats attendus
Dans un temps réduit, une exploitation quanti-quali et analyse de données de la part de groupes d’étudiants. Faire « parler » les donnés de l’INA.
Dates clés
• 2020 : Première édition sur le thème des imaginaires de l’informatique (voir rendus https://inatheque.hypotheses.org/20467 et https://inatheque.hypotheses.org/20461
• 2021 : Deuxième édition sur le thème du corps (voir présentation https://inatheque.hypotheses.org/22479 et rendus https://inatheque.hypotheses.org/23014 et https://inatheque.hypotheses.org/23148
• 2022 : Troisième édition sur le thème de l’Europe (voir présentation https://inatheque.hypotheses.org/25145
• 2023 : Quatrième édition à venir sur le thème du Sport